4 极小化DFA
问题:用子集构造法得出的 DFA 不一定是状态数最少的 DFA。
在运行下面介绍的 DFA 极小化算法之前,需要检查转换函数是不是全函数,即:需要看每个状态 s 是不是对每个可能的输入字符 a_i 都有 a_i-出边。
如果不是的话,需要添加一个死状态 s_d,满足:
- s_d 对所有可能的输入字符都转换到其本身;
- 如果某个已存在的状态 s,其对某个可能的输入字符 a_i 没有 a_i-出边,则将状态 s 的 a_i-出边指向 s_d。
这个算法需要考察的是,各个状态对所有的可能的输入字符是否去向都相同(术语名之曰“不可区分”)。
这个算法运行起来实际上很简单,但是书上的形式化表述非常的晦涩,感觉可能算法配例子会比较好理解?
这里就不贴书上的形式化表述了。
例子
这里以 HW3-1 的 NFA 转 DFA 结果为例,在那个结果中,接受状态集合是 \{E,F,G,H,I\},非接受状态集合是 \{A,B,C,D\}。
转换表如下:
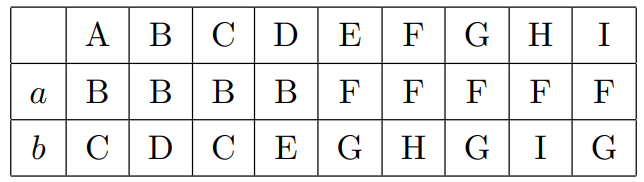
可以看到这里 A 与 C 不可区分,E、G 和 I 不可区分,将其合并,任选一个作为原来的替代,这里 A, C := A,E,G,I:=E。
现在转换表成了:
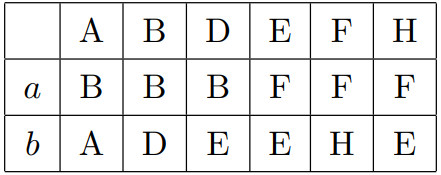
可以看到这里 E 和 H 不可区分,将其合并,任选一个作为原来的替代,E,H:=E。
现在转换表成了:
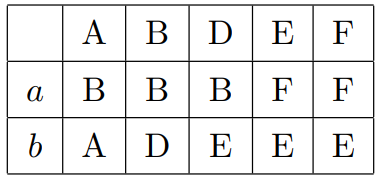
类似地,最后合并一次:
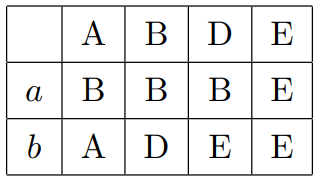
这里全都是可区分的,算法结束。
本文阅读量注意,上面的示例本身就是全函数,没有添加死状态。如果添加了死状态,要按照书上的要求:
- 如果结果 DFA 有死状态,则去掉。
- 从开始状态不可达的状态要删除。
- 从任何其他状态到死状态的转换都改成 undefined。
如果开始不是全函数,又不添加死状态,会导致新 DFA 与旧 DFA 接受不同语言。