代码生成
这里所说的代码不同于中间代码,指的是目标机器上的指令序列。
代码生成器中的问题
代码生成器的输出称为目标程序。
代码生成器必须把中间表示程序映射到能够在目标机器上执行的指令序列。
- 指令选择:选择哪些指令、生成怎样的指令(如寄存器的复用等)
- 寄存器分配:为驻留寄存器的变量选择保存其值的具体寄存器
- 计算次序选择:计算的执行次序会影响目标代码的效率
目标语言
在代码生成的一般性讨论中,不能对目标机器详细描述,因而难以为该机器完整的机器语言产生高效的代码。这里选择一种简化的多寄存器机器作为目标计算机,所提出的一些技术可用于其他许多类机器。
目标机器是字节寻址机器,一个字是 4 个字节,有 n 个通用寄存器,指令是二地址的,形式为 op\quad源\quad目的,操作码有 MOV,ADD,SUB 等。
指令中的源和目的域不够长,指令的某些位可以用来指示:下面一个字或两个字包含运算对象或地址。(附加代价的来源)
contents(a) 表示由 a 代表的寄存器或内存单元的内容。
| 地址模式 | 汇编语言形式 | 地址 | 附加代价 |
|---|---|---|---|
| 绝对地址 | M | M | 1 |
| 寄存器 | R | R | 0 |
| 变址 | c(R) | c+contents(R) | 1 |
| 间接寄存器 | *R | contents(R) | 0 |
| 间接变址 | *c(R) | contents(c+contents(R)) | 1 |
| 立即数 | \#c | c | 1 |
| 指令 | 意义 |
|---|---|
| MOV,R0,M | 把 R0 内容存入内存单元 M |
| MOV,4(R0),M | 把 contents(4+contents(R0)) 存入 M |
| MOV,*4(R0),M | 把 contents(contents(4+contents(R0))) 存入 M |
指令代价 = 1 + 源地址模式附加代价 + 目的地址模式附加代价
例子
MOV,R0,R1,代价是 1
MOV,R5,M,代价是 2,因为 M 是指令的第二个字
ADD,\#1,R3,代价是 2,因为 #1 是指令的第二个字
SUB,4(R0),*12(R1),代价是 3,因为 4 和 12 是指令的 2、3 个字
代码生成器的输入
IR 的基本块流图我们已经在前面获得了。
流图上的(程序)点和路径
流图的程序点:
- 基本块中,两个相邻的语句之间为程序的一个点
- 基本块的开始点和结束点
流图的路径:指点序列 p_1,...,p_n,且对 1\le i\le n-1,满足
- p_i 是一个语句前的点,p_{i+1} 是同一基本块中位于该语句后的点
- p_i 是某基本块的结束点,p_{i+1} 是后继块的开始点

循环
结点集合 L 是一个循环 \Leftrightarrow L 中所有结点强连通 & L 入口结点唯一
内循环:不包含其他循环的循环
支配结点:d 是 n 的支配结点(d\ \text{dom}\ n)\Leftrightarrow 从初始结点起,每条到达 n 的路径都要经过 d
- d\ \text{dom }d
- 如果 d 是循环 L 的入口,则它是 L 中所有节点的支配节点
深度优先表示:
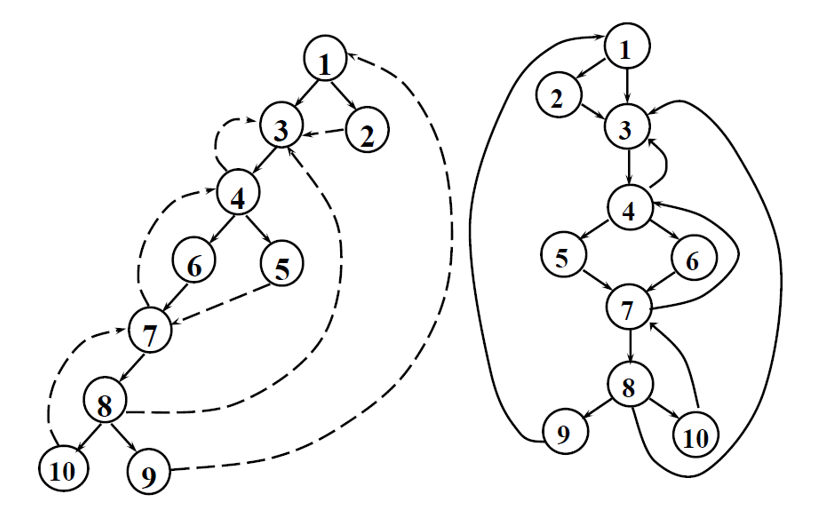
前进边:深度优先生成树上的边,m→n,这里 n 是 m 的真后代
后撤边:m→n,m 在深度优先生成树上是 n 的祖先,如 4→3 等
交叉边:m→n,二者在深度优先生成树上互不为对方的祖先,如 2→3、5→7
回边:m→n,且 n\text{ dom }m
可归约的流图:它的任何深度优先生成树上,所有的后撤边都是回边
- 如果把一个流图中所有回边删掉,剩余的图无环
流图的深度:任何可能的无环路径上最大后撤边数
自然循环
性质
- 有唯一的、支配循环所有结点的入口结点(首结点)
- 至少存在一条回边进入该循环的首结点
回边 n→d 确定的自然循环
- d 加上不经过 d 能到达 n 的所有结点
- 结点 d 是该循环的首结点
构造算法
(1)L_0=\{n,d\},标记 d 为 ”已访问“
(2)从结点 n 开始,完成对流图 G 的逆向流图的深度优先搜索,把搜索过程中访问的所有结点都加入 L_0
下次引用信息
变量接下来被使用的信息 \Rightarrow 帮助寄存器的分配和释放
计算块 B 中下次引用信息的方法
从 B 中的最后一个语句开始,反向扫描到 B 的开始处。对每个语句
- i:x=y\text{ op }z
在符号表中:
- 设置 x 为不活跃和无下次引用
- 设置 y,z 为活跃,并把他们的下次引用设置为语句 i