1 基本流程
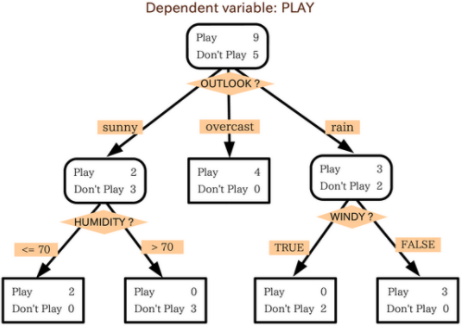
决策树的思想非常好理解,就是每一个节点 node 包含其需要处理的数据 D,其需要根据某一个属性做划分,生成两个子节点(就好像问这些数据关于一个属性的问题,正例、反例分别成为一个子节点)。
这样来看,叶子节点包含的数据一定是同一个类型的了。
注意,即使我们做二分类任务,决策树也不一定是二叉树,因为对于某个节点,依据某一个属性(假设有 |V| 种取值)做划分的时候可以生出 |V| 个子节点。
思想很简单,但是有下面一些需要考虑的事情:
- 需要在实现上(比如划分时)做一些优化,避免节点过多造成的运算时间和空间开销
- 如果没有数据冲突,总能生成训练集上 100% 准确的决策树,但是泛化性能可能不好,需要剪枝处理
- 对连续的值如何选择一个区间进行划分?(如 A>0.3→+)对于有缺失值的数据又怎么处理?
后面几节将围绕这几个问题来做些讨论。
本文阅读量