3 Bagging
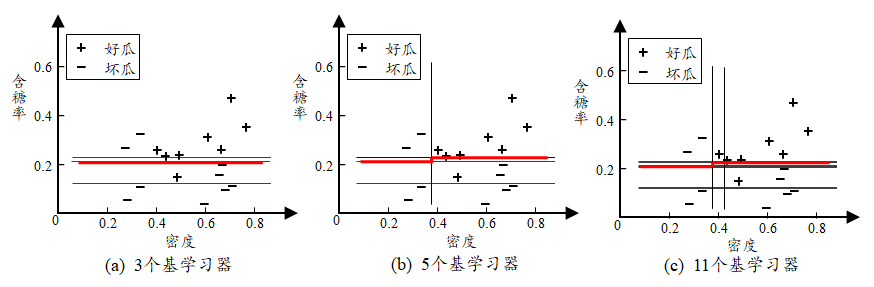
个体学习器不存在强依赖关系、并行化生成
基学习器尽可能具有较大的差异
- 对训练样本进行采样,产生出不同的子集,再从每个子集中训练出一个基学习器
- 若采样出完全不同的子集,每个基学习器只用到一小部分训练数据,可能不足以进行有效学习,无法确保基学习器的性能
解决办法:
- 自助采样法:对数据集 D 有放回采样 m 次得到训练集 D'
- 某样本始终不被采样到的概率 =\lim_{m\to\infty}(1-\frac1m)^m=\frac1e
- 初始训练集中约有 63% 样本出现在训练集中
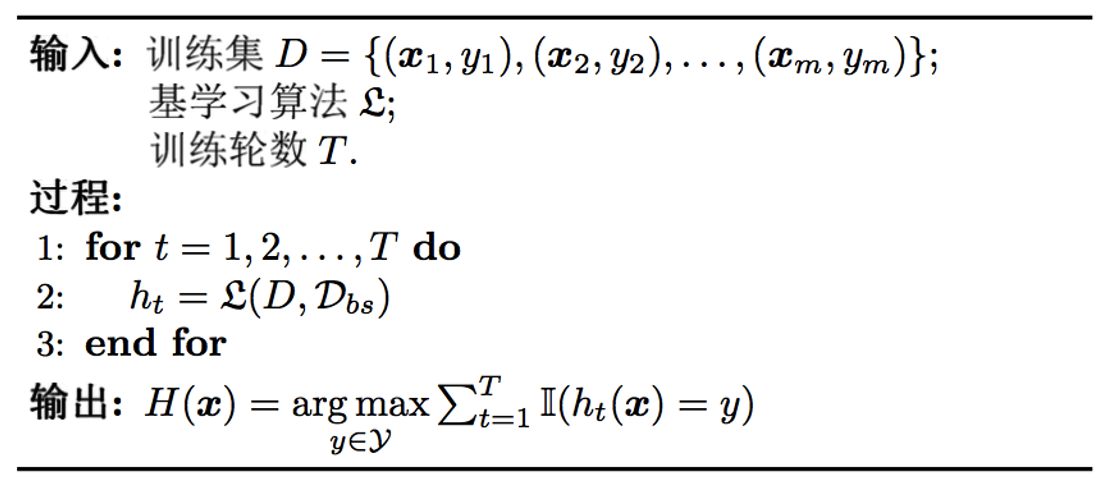
这里 \mathcal{D}_{bs} 就是一次自助采样得到的测试集,结果是投票/平均产生的
优点:时间复杂度低
- 假定个体学习器的计算复杂度为 O(m),采样与投票/平均过程的复杂度为 O(s),则 bagging 的复杂度大致为 T(O(m)+O(s))
- O(s) 很小且 T 是一个不大的常数
- 训练一个 bagging 集成与直接使用基学习器的复杂度同阶 —— 高效
由于个体学习器并未使用全部训练数据,因此其余数据可用作验证集对泛化性能进行包外估计(oob) $$ H^{oob}(x)=\arg\max_{y\in\mathcal{Y}}\sum_{t=1}^T\mathbb{I}(h_t(x)=y)\mathbb{I}(x\not\in D_t) $$
\epsilon^{oob}=\frac{1}{|D|}\sum_{(x,y)\in D}\mathbb{I}(H^{oob}(x)=y)
从偏差-方差的角度:降低方差,在不剪枝的决策树、神经网络等易受样本影响的学习器上效果更好