3 原型聚类
此类算法假设聚类结构能通过一组原型刻画,原型是指样本空间中具有代表性的点。
通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解。
k- 均值算法
最小化平方误差: $$ E=\sum_{i=1}^k\sum_{x\in C_i}||x-\mu_i||_2^2 $$ 这里 \mu_i 是簇 C_i 的均值向量,即 \mu_i=\frac{1}{|C_i|}\sum_{x\in C_i} x
E 越小,簇内样本相似度越高
k-means 算法采用贪心策略,通过迭代优化来近似求解 E 的最小值

也可以改写 E 的写法,引入
- \mu^T=[\mu_1,...,\mu_k],\mu\in\mathbb{R}^{k\times d}
- t_i^T=[0,...,1,...,0]\in\{0,1\}^{1\times k} 是仅在第 i 位为 1 的向量
- T^\top=[t_1^\top,...,t_m^{\top}],T\in \{0,1\}^{m\times k}
则 $$ E(T,\mu)=\sum_{i=1}^m||x_i-t_i^\top\mu||_2^2=||X-T\mu||_F^2 $$ 意义上就是:把每个向量和其所属的簇的中心点(由 t_i^\top\mu 算出)求距离,并全部加起来
优化问题就变成了 \displaystyle \min_{T,\mu}E(T,\mu),算法流程可以改写为:

计算 T^{(t)}\leftarrow\min_T E(T,\mu^{(t-1)})
因为样本间互不依赖,所以对于 T 的每一行,可以独立地去求 $$ \min_{t_i}||x_i-t_i^\top\mu||_2^2=\min_c||x_i-\mu_c||_2^2 $$
计算 \mu^{(t)}\leftarrow \min_{\mu}E(T^{(t)},\mu)
因为 \mu 是连续的,可以直接求 E(T,\mu) 关于 \mu 的梯度,令其等于 0,解得 \mu=(T^TT)^{-1}T^TX
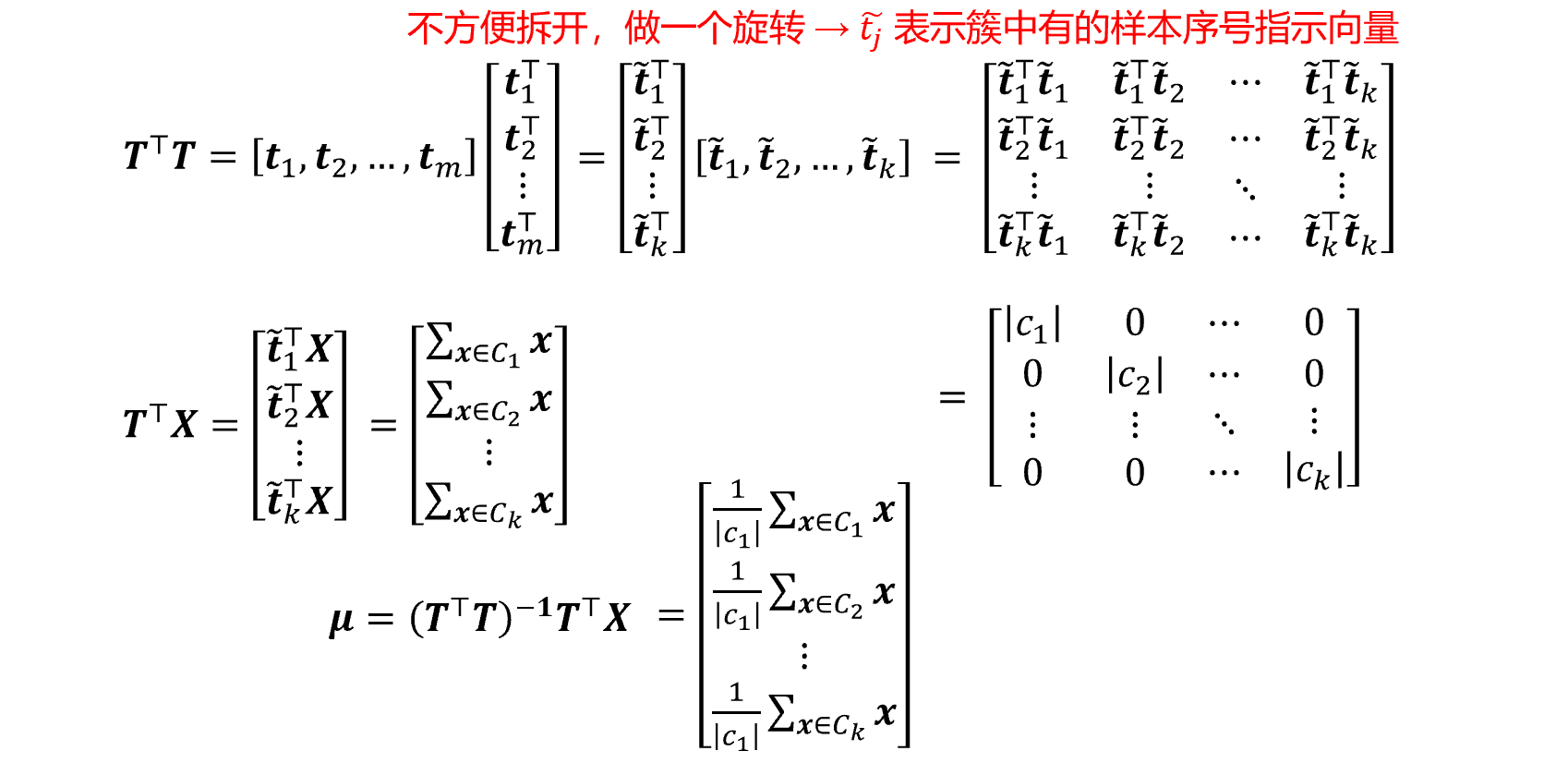
上面是用迭代的方法,如果松弛 T,使之可以在 [0,1] 之间取值,但是要满足每行各元素之和为 1,然后就可以用梯度下降法,求出来之后再离散化即可。
学习向量量化(LVQ)
- 与 k-means 相同:也是试图找到一组原型向量
- 不同:LVQ 假设数据样本带有类别标记,学习过程中利用样本的这些监督信息来辅助聚类
给定:
- 样本集合 D=\{(x_1,y_1),...,(x_m,y_m)\}(x_i 假设是 n 维的)
- y_i\in\mathcal{Y} 是每个样本的类别标记
LVQ 的目标是学得一组 n 维原型向量 \{p_1,...,p_q\},每个原型向量代表一个 Cluster

高斯混合聚类
- 不是用原型向量来刻画聚类结构,而是用概率模型来表达聚类原型
- 设 x 是服从 d 维高斯分布的随机向量,其密度函数是
定义高斯混合分布 $$ p_\mathcal{M}(x)=\sum_{i=1}^k\alpha_ip(x|\mu_i,\Sigma_i) $$ 其中 \sum\alpha_i=1,所以 p_\mathcal{M}(x) 也是一个概率密度函数
假设样本生成的过程如下:
- 先定义先验分布 \alpha_1,...,\alpha_k,其中 \alpha_k 是选择第 k 个成分的概率
- 然后被选择的混合成分的概率密度函数进行采样,从而生成相应的样本
可以用极大似然估计去反推诸 \alpha,\mu,\Sigma(分别求对数似然关于这些参数的偏导数,令其等于 0,解出这些参数)
本文阅读量