3 多层前馈神经网络
注
由于这一章实际上课感觉更偏介绍性,这里不少笔记都是照搬PPT的。
定义:每层神经元与下一层神经元全互联,神经元之间不存在同层连接也不存在跨层连接
前馈:输入层接受外界输入,隐含层与输出层神经元对信号进行加工,最终结果由输出层神经元输出
学习:根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的“阈值”
多层网络:包含隐层的网络
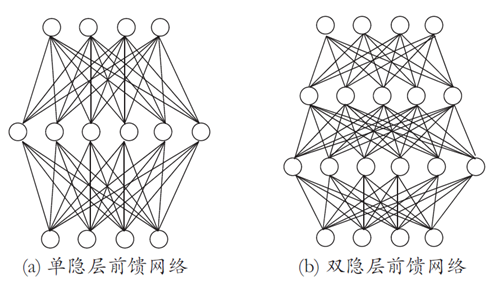
表示能力
只需要一个包含足够多神经元且具有任何 “挤压” 性质的激活函数的隐层,多层前馈神经网络就能以任意精度逼近有界闭集上的任意连续函数。
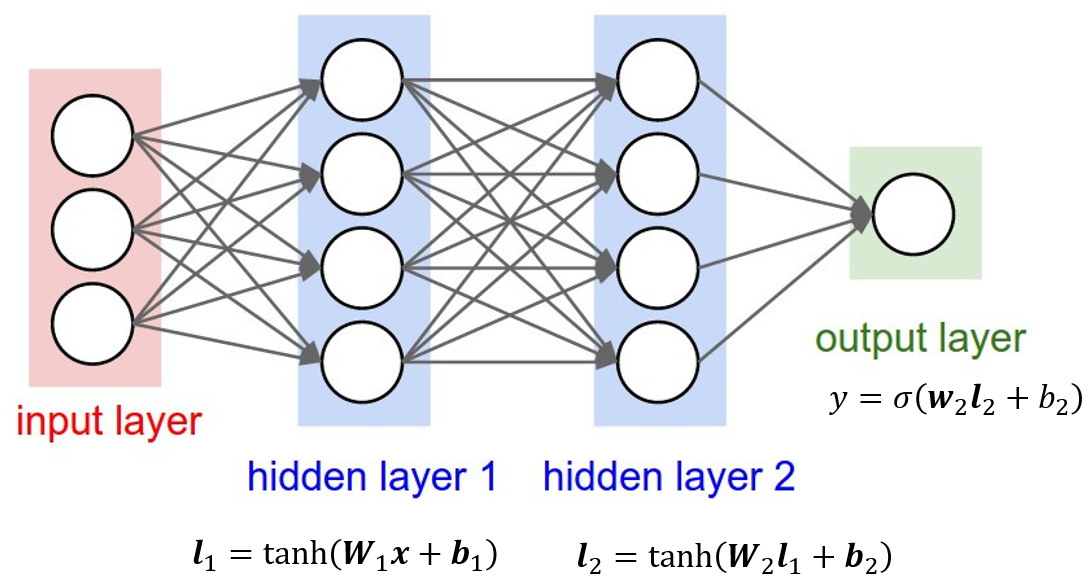
BP 算法
误差逆传播算法(Error BackPropagation,简称BP)是最成功的训练多层前馈神经网络的学习算法。
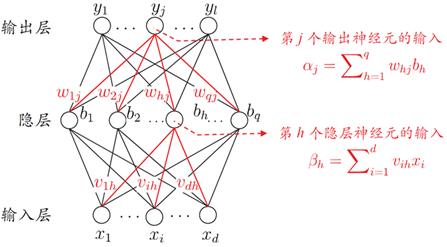
| 记号 | 定义 |
|---|---|
| l | 输出向量 Y=(y_1,...,y_l) 的维度,也是输出层神经元个数 |
| d | 输入向量 x=(x_1,...,x_d) 的维度,也是输入层神经元个数 |
| q | 隐藏层神经元个数 |
| \theta_j | 输出层第 j 个神经元的阈值 |
| w_{hj} | 隐藏层第 h 个神经元与输出层第 j 个神经元的连接权重 |
| \gamma_h | 隐藏层第 h 个神经元的阈值 |
| v_{ih} | 输入层第 i 个神经元与隐藏层第 h 个神经元的连接权重 |
所以网络中包含的参数个数为:权重参数个数 + 阈值参数个数 $$ (l\times q)+(d\times q)+l+q $$ BP 也是一个迭代学习算法,每轮迭代参数都要进行更新。v←v+\Delta v
假设隐藏层和输出层的激活函数都使用 \sigma(x),则对于输出的预报向量 \hat Y=(\hat y_1,...,\hat y_l),其每一个分量为 $$ \hat y_j=f(\alpha_j-\theta_j) $$ \alpha_j 是上面图中定义的量。这样我们的 loss 函数可采用均方误差: $$ E_k=\frac12\sum_{j=1}^l(\hat y_j^{(k)}-y_j^{(k)})^2 $$ 这里等号左边的下标 k 和右边的上标 k 表示的是第 k 个样本。
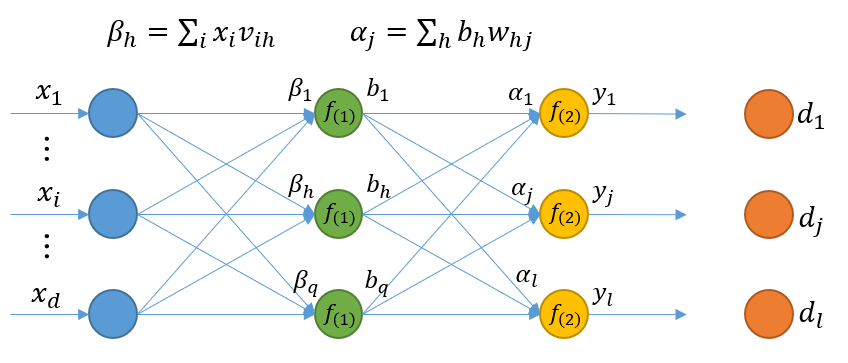
前向的传播关系:
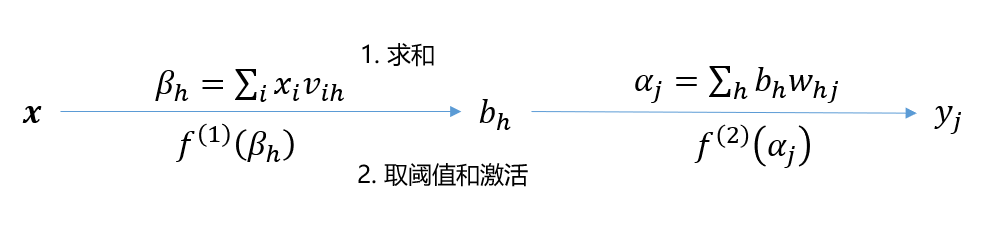
BP 算法更新参数使用的是梯度下降策略,在第 k 个样本上,w_{hj} 的更新公式为
$$
w_{hj}←w_{hj}-\eta \frac{\partial E_k}{\partial w_{hj}}
$$
这个偏导数项很好计算,利用 E_k 和 \hat y_j 的定义式做链式法则即可,也可以从图上从右往左来看。
$$
\frac{\partial E_k}{\partial w_{hj}}=\frac{\partial E_k}{\partial \hat y_j}·\frac{\partial \hat y_j}{\partial \alpha_j}·\frac{\partial \alpha_j}{\partial w_{hj}}:=g_jb_h
$$
同理,在计算 v_{ih} 的更新量时,链式法则也是图中从右往左,但是注意,输出层所有的神经元都与某个隐层神经元有关,所以要求一个和,计算式稍微复杂一点
$$
\frac{\partial E_k}{\partial v_{ih}}=\sum_j\frac{\partial E_k}{\partial \hat y_j}·\frac{\partial \hat y_j}{\partial \alpha_j}·\frac{\partial \alpha_j}{\partial b_{h}}·\frac{\partial b_h}{\partial \beta_{h}}·\frac{\partial \beta_h}{\partial v_{ih}}:=e_hx_i
$$

在上面这个算法中,\displaystyle{}g_j=\frac{\partial E_k}{\partial \hat y_j}·\frac{\partial \hat y_j}{\partial \alpha_j},\displaystyle{}e_h=\sum_j\frac{\partial E_k}{\partial \hat y_j}·\frac{\partial \hat y_j}{\partial \alpha_j}·\frac{\partial \alpha_j}{\partial b_{h}}·\frac{\partial b_h}{\partial \beta_{h}}
梯度下降的选择
还记得上面的 k 吗,意思是说对一个训练样例就可以做一次或者多次的参数更新。
- 标准 BP(随机 BP)每次针对单个训练样例更新参数。但是参数更新频繁,以及不同样例对参数的影响可能抵消,开销大且可能做无用功。
- 累计 BP 优化目标则改成整个训练集上的累计误差,即 E=\frac1m\sum_{k=1}^mE_k,读取整个训练集一遍之后,才更新参数。这样的更新频率是比较低的。
注
但在很多任务中,累计误差下降到一定程度后,进一步下降会非常缓慢,这时标准BP算法往往会获得较好的解,尤其当训练集非常大时效果更明显。
- 小批量随机梯度下降,是指每次选择一小部分样例 n<<m 来做更新,即 $$ \frac{\partial E}{\partial \theta}=\frac{1}{m}\sum_k^m\frac{\partial E_k}{\partial \theta}\sim\frac1n\sum_i^n\frac{\partial E_i}{\partial \theta} $$ 这里面 n 的大小被称为一个 Batch。
多层前馈的局限性
