7 布尔表达式和控制流语句
主要任务
- 布尔表达式的计算:完全计算、短路计算
- 控制流语句(分支结构 if, switch、循环结构、过程/函数的调用)
- 各子结构的布局 + 有(无)条件转移指令
- 跳转目标的两种处理方法:标号技术、回填技术
布尔表达式
布尔表达式的作用
- 计算逻辑值
- 作为控制流语句中的条件
相关文法
- B → B or B | B and B | not B | (B) | E relop E | true | false
布尔表达式的计算
完全计算:各个子表达式都要计算
短路计算:
- B~1~ or B~2~ 定义成 if B~1~ then true else B~2~
- B~1~ and B~2~ 定义成 if B~1~ then B~2~ else false
控制流语句的翻译
相关文法
S -> if B then S1
| if B then S1 else S2
| while B do S1
| switch E begin
case V1: S1
...
case vk: Sk
default: Sm
end
| call id(Elist)
| S1; S2
if 语句的中间代码布局
问题
- B 的短路计算中,需要知道其为 true 或 false 时的跳转目标
- B、S~1~、S~2~ 分别会发射多少条指令是不确定的
对策1:标号技术
B.code、S.code 都表示三地址代码
B.true、S.begin、S.next 等都是三地址指令的标号,都是继承属性
- 引入标号:先确定标号,在目标确定时发射标号指令
- 调用 newLabel () 产生新标号,每条语句有 next 标号
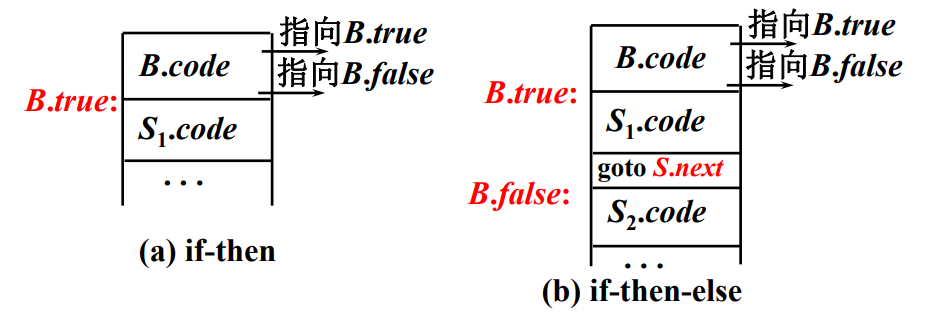
- S → if B then S~1~
- S → if B then S~1~ else S~2~
visitIf-then:
访问 B 前:
B.true = newLabel();
// 因为并不知道 B 有多少条语句,所以 S1 的第一条语句先用 newLabel 标记
B.false = S.next;
// S.next 是执行完 S 后应该执行的第一条三地址指令的标号
进入 S~1~ 前:
S1.next = S.next;
访问 S~1~ 后:
S.code = B.code || gen(B.true, ':') || S1.code;
// gen 把形成的代码串作为函数值,而不是像 emit 一样输出到文件上
// || 是串的连接算符
// 此时已经读完 B,函数 gen(B.true, ':') 定位了 newLabel 具体的位置
visitIf-then-else:
访问 B 前:
B.true = newLabel();
B.false = newLabel();
进入 S~1~ 前:
S1.next = S.next;
进入 S~2~ 前:
S2.next = S.next;
访问 S~1~ 后:
S.code = B.code || gen(B.true, ':') || S1.code || gen('goto', S.next) || gen(B.false, ':') || S2.code
对策2:回填技术
上面的标号技术在确定 newLabel 位置时又进行了一趟处理,一共需要两趟,下面所说的回填技术是只需要一趟处理的,思路如下:
- 把跳转到同一个标号的指令放到同一张指令表中
如,为 B 引入综合属性 trueList 和 falseList 分别收集要回填的跳转指令;为 S 引入 nextList 收集要回填的跳转指令
- 等目的标号确定时,再把它填到表中的各条指令中,同一个列表中的所有跳转指令的目标标号相同
mkList (i) 创建一个只包含 i 的列表,i 是指令数组的下标,返回这个表的指针
merge (p1, p2)将 p1 和 p2 指向的列表进行合并,返回合并后列表的指针
backPatch (p, i) 将 i 作为目标标号插入 p 所指列表的指令中
nextinstr 是全局变量,保存了紧跟着的下一条指令的序号
详见龙书 265 页
visitIf-then:
访问 S~1~ 前:
instr = nextinstr;
访问 S~1~ 后:
backPatch(B.trueList, instr); // 回填
S.nextList = merge(B.falseList, S1.nextList);
visitIf-then-else:
访问 S~1~ 前:
instr1 = nextinstr;
访问 S~1~ 后:
nextList = mkList(nextinstr);
emit('goto _');
访问 S~1~ 前:
instr2 = nextinstr;
访问 S~1~ 后:
backPatch(B.trueList, instr1);
S.nextList = merge(merge(S1.nextList, nextList), S2.nextList);
while 语句和顺序结构
- 引入开始标号 S.begin,作为循环的跳转目标
- 为每一语句 S_1 引入其后的下一条语句的标号 S_1.next(顺序结构)
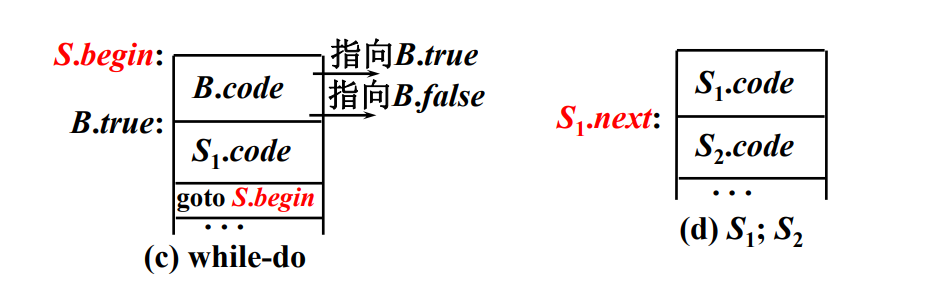
标号技术
- S → while B do S~1~
访问 while 前:
S.begin = newLabel();
访问 B 前:
B.true = newLabel();
B.false = S.next();
进入 S~1~ 前:
S1.next = S.begin;
访问 S~1~ 后:
S.code = gen(S.begin, ':') || B.code || gen(B.true, ':') || S1.code || gen('goto', S.begin);
回填技术
- S → while B do S~1~
访问 B 前:
instr1 = nextinstr;
进入 S~1~ 前:
instr2 = nextinstr;
访问 S~1~ 后:
backPatch(S1.nextList, instr1);
backPatch(B.trueList, instr2);
S.nextList = B.falseList;
emit('goto', instr1);
布尔表达式的翻译
使用标号技术
- B → B~1~ or B~2~
访问 B~1~ 前:B1.true = B.true; B1.false = newLabel();
访问 B~2~ 前:B2.true = B.true; B2.false = B.false;
访问 B~2~ 后:B.code = B1.code || gen(B1.false, ':') || B2.code;
- B → not B~1~
访问 not 前:B1.true = B.false; B1.false = B.true;
访问 B~1~ 后:B.code = B1.code;
- B → B~1~ and B~2~
访问 B~1~ 前:B1.true = newLabel(); B1.false = B.false;
访问 B~2~ 前:B2.true = B.true; B2.false = B.false;
访问 B~2~ 后:B.code = B1.code || gen(B1.true, ':') || B2.code;
- B → (B~1~)
访问 ( 前:B1.true = B.true; B1.false = B.false;
访问 ) 后:B.code = B1.code;
- B → E~1~ relop E~2~
访问 E~2~ 后:
B.code = E1.code || E2.code || gen('if', E1.place, relop.op, E2.place, 'goto', B.true) || gen('goto', B.false);
- B → true
访问 true 后:B.code = gen('goto', B.true);
- B → false
访问 false 后:B.code = gen('goto', B.false);
使用回填技术
- B → B~1~ or M B~2~
backPatch(B1.falseList, M.instr);
B.falseList = B2.falseList;
B.trueList = merge(B1.trueList, B2.trueList);
- M → ε
M.instr = nextinstr;
- B → B~1~ and M B~2~
backPatch(B1.trueList, M.instr);
B.trueList = B2.trueList;
B.falseList = merge(B1.falseList, B2.falseList);
- B → not B~1~
B.trueList = B1.falseList;
B.falseList = B1.trueList;
- B → (B~1~)
B.trueList = B1.trueList;
B.falseList = B1.falseList;
- B → E~1~ relop E~2~
B.trueList = mkList(nextinstr);
B.falseList = mkList(nextinstr + 1);
emit('if', E1.place, relop.op, E2.place, 'goto _');
emit('goto _');
- B → true
B.trueList = mkList(nextinstr);
B.falseList = null;
emit('goto _');
- B → false
B.falseList = mkList(nextinstr);
B.trueList = null;
emit('goto _');
switch 语句的翻译
switch E
begin
case V1:S1
case V2:S2
...
case Vj:Sj
case Vk:Sk
default: Sm
end
这里 S~i~ 执行后就退出 switch,相当于 C 中每个 case 处理后有 break
分支数较少时
t = E 的代码
if (t != V1) goto L1;
S1 的代码
goto next
L1: if (t != V2) goto L2;
S2 的代码
goto next
L2: ...
Lj: if (t != Vk) goto Lk;
Sk 的代码
goto next
Lk: Sm 的代码
next:
当要多次判断 t 的值时,由于跳转目标不是邻近的语句,代码的局部性不好,会引起比较多的 cache miss,代码性能不高
分支数较多时
将分支测试代码集中在一起,便于生成较好的分支测试代码
t = E 的代码
goto T
L1: S1 的代码
goto next
L2: S2 的代码
goto next
...
Lk: Sk 的代码
goto next
Lm: Sm 的代码
goto next
T: if (t == V1) goto L1;
if (t == V2) goto L2;
...
if (t == Vk) goto Lk;
next:
多次判断 t 的值的代码是邻近的,改善代码局部性,降低 cache miss,代码性能好
case 语句
中间代码增加一种 case 语句,便于代码生成器对其进行特别处理
T: case V1 L1
case V2 L2
...
case Vk Lk
case t Lm
next:
代码生成器可做的优化:
- 使用二分查找确定需要执行的分支
- 建立入口地址表,直接找到需要执行的分支
过程调用的翻译
相关文法
- S → call id (Elist)
- Elist → Elist, E
- Elist → E
id(E~1~, E~2~, ..., E~n~) 的中间代码结构
E1.place = E1 的代码
E2.place = E2 的代码
...
En.place = En 的代码
param E1.place
param E2.place
...
param En.place
call id.place, n
翻译
- S → call id (Elist)
结尾:长度为 n 的队列中的每个 E.place
for (each E.place)
emit('param', E.place);
emit('call', id.place, n);
- Elist → Elist, E
结尾:把 E.place 放入队列末尾
- Elist → E
结尾:将队列初始化,使它仅含 E.place
本文阅读量