2 多个活动记录的组织
进程地址空间和静态分配
静态分配:
- 名字在编译时绑定到存储单元,不需要运行时支持
- 生存期是程序的整个运行期间
纯静态分配语言的限制:
- 不允许递归过程
- 数据对象的长度和内存中的位置必须编译期确定
- 数据结构不能动态建立
Linux 的地址布局:
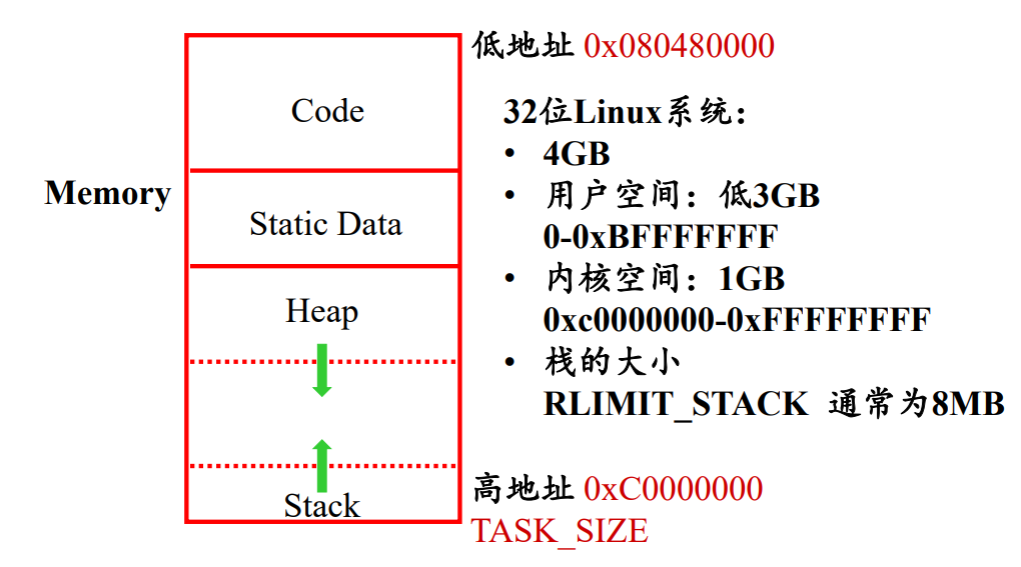
C 语言的存储分配
声明在函数外
- 外部变量 extern(静态分配)
- 静态外部变量 static(静态分配,改变作用域)
声明在函数里面
- 静态局部变量 static(静态分配,改变生存期)
- 自动变量 auto(在活动记录中)
活动树和运行栈
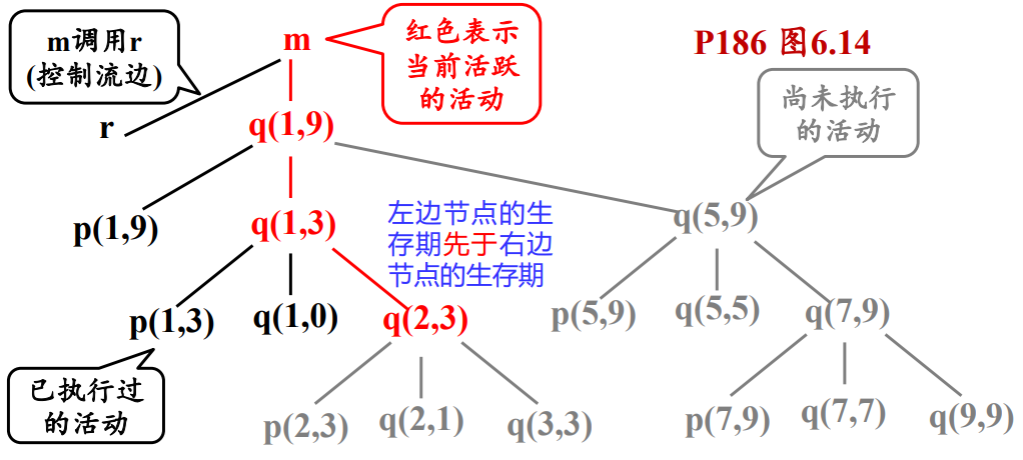
活动树:用树来描绘控制进入和离开活动的方式
- 每个结点代表某过程的一个活动
- 根结点代表主程序的活动
- 结点 a 是结点 b 的父结点 \Leftrightarrow 控制流从 a 的活动进入 b 的活动
- 结点 a 处于结点 b 的左边 \Leftrightarrow a 的生存期先于 b 的生存期
运行栈:当前活跃的活动保存在一个栈中
- 把控制栈中的信息拓广到包括过程活动所需的所有局部信息(即活动记录)
活动记录的设计的一些原则
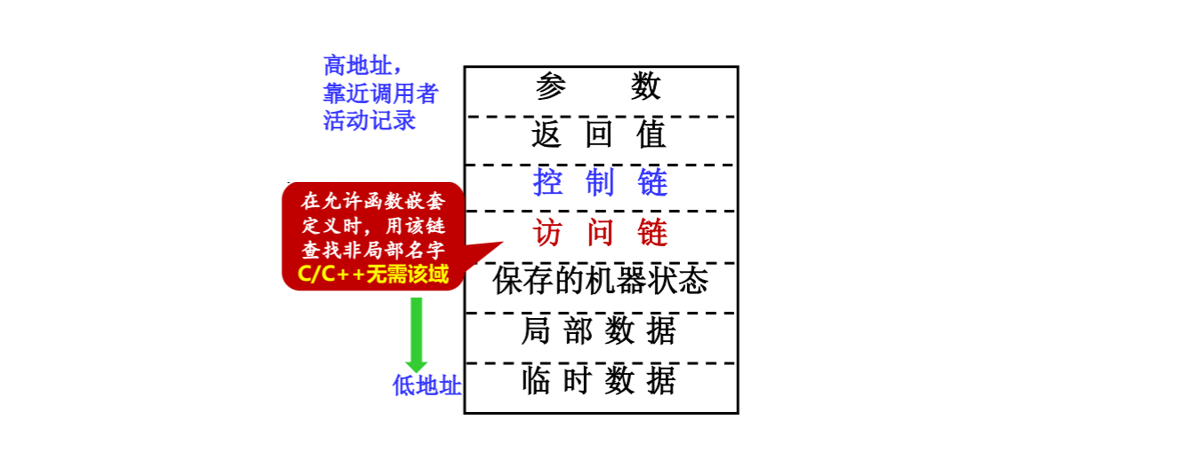
以活动记录(大小不确定)中间的某个位置作为基地址(一般是控制链)
长度能较早确定的域放在活动记录的中间
一般包括控制链、访问链和机器状态域。如果每次调用时正好保存机器状态中同样的成分,那么可以执行同样的代码来完成机器状态的保存和恢复。而且,如果机器状态信息是标准化的,那么出现错误时,调试器等程序可以很轻松地解读运行栈的内容。
一般把临时数据放在局部数据域的后面
有些局部变量的大小在程序运行前一直不能确定,最常见的例子是动态大小的数组。
把参数域和返回值域(可能有)放在紧靠调用者活动记录的地方(有的用寄存器传参数和返回值)
这样做便于调用者p在被调用者q的完整活动记录建立起来之前就可以把实参的值放到自身活动记录的顶端;这样做还允许使用参数个数可变的过程,这个问题后面再讨论。
用同样的代码来执行各个活动的保存和恢复
因为上面的设计原则告诉了我们先是定长、后是不定长,所以处理代码可以标准化。
过程调用序列:p 调用 q
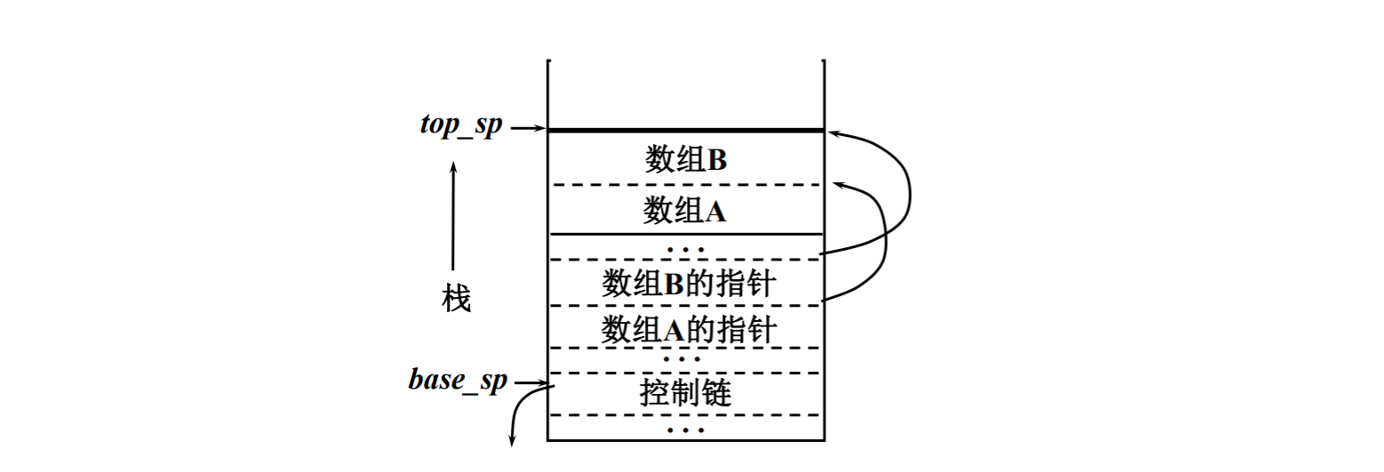
给出一种调用者和被调用者怎样协作管理栈的建议(无须访问链的语言)。
-
寄存器 top\_sp 指向栈顶活动记录的末端;
-
寄存器 base\_sp 指向栈顶活动记录中控制链所在的位置,它作为访问栈顶活动记录中内容的基地址。
假定过程 p 调用过程 q,调用序列如下。
(1)p 计算实参,依次将它们压入栈顶,也就是放到 q 的活动记录中,并在栈顶上留出放返回值的空间。(top\_sp 不断减小)
参数个数可变场合难以确定存放返回值的位置,因此通常用寄存器传递返回值。
编译器产生将实参表达式逆序计算并将结果进栈的代码。
为提高参数传递的效率,不是用 push 指令将参数逐个压栈,而是先修改 esp 的值,空出所需的参数区,然后用 movl 指令将实参逐个进栈。
(2)p 把返回地址压入 q 的活动记录,把控制转到 q。
(3)q 将要保存的寄存器(base\_sp 除外)的值和其他机器状态信息压入栈,然后把 base\_sp 的当前值(p 的)压入栈,然后把当前 top\_sp 作为自己 base\_sp 的值。
把 p 的 base\_sp 压入栈就是建立控制链,由于控制链是按运行时过程调用关系从被调用者的活动记录指向调用者的活动记录,因此控制链也称为动态链。
(4)q 根据局部数据域和临时数据域的大小来减小 top\_sp 的值,也就是进行局部数据和临时数据的空间分配,并初始化它的局部数据,开始执行过程体。
返回序列如下。
(1)q 把返回值置入活动记录中存放返回值的地方。
(2)与调用序列的步骤(4)相对应,q 增加 top\_sp 的值。
(3)q 恢复寄存器(包括 base\_sp)和机器状态,把控制转到 p。
(4)与调用序列的步骤(1)相对应,p 增加 top\_sp 的值,并取出返回值。
栈上存储可变长数据
如何在栈上布局可变长数组?
- 先分配存放数组指针的单元,对数组的访问通过指针间接访问
- 运行时,这些指针指向分配在栈顶的数组存储空间