3 线性判别分析
基本思路
把数据集上的点投影到低维空间(比如直线),使得
- 同类样例的投影点尽可能接近
- 异类样例的投影点尽可能远离
- 新样本投影后可以根据投影位置进行判别
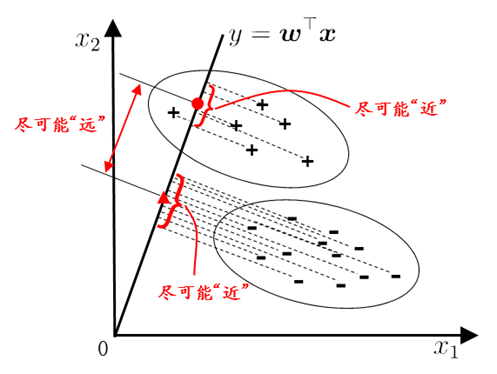
数据定义
给定数据集 D=\left\{\left(\boldsymbol{x}_i, y_i\right)\right\}_{i=1}^m, y_i \in\{0,1\}
- 第 c 类示例的集合 X_c
- 第 c 类示例的均值向量 \boldsymbol{\mu}_c=\frac{1}{\left|X_c\right|} \sum_{x \in X_c} \boldsymbol{x}
- 第 c 类示例的协方差矩阵 \boldsymbol{\Sigma}_c=\sum_{x \in X_c}\left(\boldsymbol{x}-\boldsymbol{\mu}_c\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_c\right)^{\top}
若将数据投影到方向 \boldsymbol{w} 确定的直线上
- 第 c 类样本的中心在直线上的投影 \frac{1}{\left|X_c\right|} \sum_{\boldsymbol{x} \in X_c} \boldsymbol{w}^{\top} \boldsymbol{x}=\boldsymbol{w}^{\top} \boldsymbol{\mu}_c
- 第 c 类样本的协方差 \sum_{\boldsymbol{x} \in X_c}\left(\boldsymbol{w}^{\top} \boldsymbol{x}-\boldsymbol{w}^{\top} \boldsymbol{\mu}_c\right)^2=\boldsymbol{w}^{\top} \boldsymbol{\Sigma}_c \boldsymbol{w}
优化计算
- 同类的投影点的协方差尽可能小
- 异类样本中心投影距离尽可能大
二分类情形
在二分类情形下,最大化优化目标可以是 $$ J=\frac{\left|\boldsymbol{w}^{\top} \boldsymbol{\mu}_0-\boldsymbol{w}^{\top} \boldsymbol{\mu}_1\right|_2^2}{\boldsymbol{w}^{\top} \Sigma_0 \boldsymbol{w}+\boldsymbol{w}^{\top} \boldsymbol{\Sigma}_1 \boldsymbol{w}}=\frac{\boldsymbol{w}^{\top}\left(\boldsymbol{\mu}_0-\boldsymbol{\mu}_1\right)\left(\boldsymbol{\mu}_0-\boldsymbol{\mu}_1\right)^{\top} \boldsymbol{w}}{\boldsymbol{w}^{\top}\left(\boldsymbol{\Sigma}_0+\boldsymbol{\Sigma}_1\right) \boldsymbol{w}}=\frac{\boldsymbol{w}^{\top} \boldsymbol{S}_b \boldsymbol{w}}{\boldsymbol{w}^{\top} \boldsymbol{S}_w \boldsymbol{w}} $$ 第二个等号是代数变形,参见南瓜书。
类间散度 S_b:=(\mu_0-\mu_1)(\mu_0-\mu_1)^T,类内散度 S_w=\Sigma_0+\Sigma_1
第三个等号导出的式子叫做“广义瑞利商”。
若 w 是一个解,则任意常数 \alpha,\alpha w 也是一个解,所以可以令 w^TS_ww=1,这个优化问题变成了 $$ \max _w w^TS_b w\quad\text{s.t. }w^TS_ww=1 $$
由拉格朗日乘子法(参见南瓜书),我们需要的 w 是方程 S_bw=\lambda S_ww 的解。注意到 S_bw=(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw = (\mu_0-\mu_1)*R, R 是一个标量,所以 S_b 的方向恒为 \mu_0-\mu_1 的方向,不妨设 $$ S_bw=\lambda(\mu_0-\mu_1) $$ 带入 S_bw=\lambda S_ww 可知 w=S_w^{-1}(\mu_0-\mu_1)。
注
在实践中通常对 S_w 做奇异值分解,让 S_w=U\Sigma V^T,\Sigma 是实对角矩阵,对角线上元素是奇异值,然后 S_w^{-1}=V\Sigma^{-1}U^T。
多分类情形
假设存在 N 个类,第 i 类的示例数为 m_i。这里的定义还是可以参考书上 P62,主要提一下这里的优化目标。
书上的优化目标是 \displaystyle\max_W\frac{tr(W^TS_bW)}{tr(W^TS_wW)},这样由拉格朗日乘数法得到的解满足 S_bW=\lambda S_w W,但是这个式子导致矩阵 W 每一列对应的特征值都一样,即 \lambda:=diag(\lambda,...,\lambda),实际上应该要不一样。
其他的书提出优化目标为 \displaystyle\max_W\frac{det(W^TS_bW)}{det(W^TS_wW)},则由拉格朗日乘数法得到的解满足 S_bW=\Lambda S_w W,左乘 S_w^{-1} 可得 $$ S_w^{-1}S_bW=W\Lambda $$ 如果 S_w 是一个非奇异矩阵,并且可以求逆,那么当投影矩阵 W 由 S_w^{-1}S_b 的特征向量组成时,取到最大化。
多分类学习任务
从二分类任务推广到多分类任务,主要是一种“拆分”的思想。
假设存在 N 个类,第 i 类的示例数为 m_i。
- OvO(One vs. One)
想法是把 N 个类两两配对,产生 C_n^2 个二分类任务。最终结果通过 C_n^2 个分类器的结果投票决定。
- OvR(One vs. Rest)
想法是产生 N 个二分类(i 为一类,其余为一类)任务。最终结果选择置信度最大的正例类别。
- MvM(Many vs. Many)
想法是每次将若干类作为一类,其他类作为另一类。
ECOC
ECOC(Error Correcting Output Codes,纠错输出码)是最常用的 MvM 技术,做法如下:
- 每个类别 i 给予一个长度为 M 的编码
- 对 N 个类别做 M 次上述划分,训练出 M 个分类器 f_1,...,f_M
- 对于每个测试样例,送入 M 个分类器得到一个编码,与所有既有编码求距离(比如汉明距离,欧氏距离),选最小的
类别不平衡问题
- 再缩放:由测试阈值替代实际阈值(假设无偏)
- 欠采样、过采样